Working on Plato Texts
I started working on some Plato texts a while ago but now I'm back to it, integrating various information and hitting some more issues with the Diorisis corpus.
About a year ago, I wrote about some vocabulary statistics I'd put together around various texts. This included a subcorpus of Plato I wanted to put together for the Greek Learner Texts Project. Based on the "core" works list I'd put together for https://vocab.perseus.org, this included:
- Euthyphro
- Apology
- Crito
- Symposium
- Republic
At the time, I used Giuseppe Celano's experimental lemmatization as the basis for the vocabulary counts.
In the intervening period, I went further with Crito and restructured the citation scheme to be based on units of dialogue and sentences. You can see HTML generated from the result at:
https://jtauber.github.io/plato-texts/
but the underlying data is available at https://github.com/jtauber/plato-texts/blob/master/text/crito.txt.
I also took a first pass at aligning an English translation at the sentence level and the raw data for that is available at https://github.com/jtauber/plato-texts/blob/master/analysis/crito_aligned.txt.
My plan was always to return to the other four texts and last weekend I started on that, freshly bringing in the texts (in both Greek and English) from Perseus, the Diorisis corpus tagging, and the treebanks from AGLDT (Euthyphro) and Vanessa Gorman (the Apology).
I also added:
and may add others if they seem appropriate for the Greek Learner Texts Project.
The first thing I did was produce a stripped-down tokenized version of the Greek texts from Perseus with minimal markdown. In this process, I found a small number of issues with the Perseus XML which I'll submit corrections for shortly (mostly some stray gammas).
I then wrote a script to extract similar tokens from Diorisis for alignment. As I've written about before, the Diorisis corpus made the odd choice to use betacode for the tokens so I had to do a conversion. Then the real fun began.
Firstly, the Perseus text, based on the Burnet edition, has various editorial markup like <add>, <del>, <corr>, <sic>. I quickly discovered that the Diorisis text drops the <del> and <sic> elements. That's fine although I might seek the advice of people more familiar with Burnet and the text scholarship of Plato as to what the Greek Learner Texts edition should do.
Secondly, in Phaedo at least, named entities are marked up in the Perseus TEI XML. People and places are all appropriately tagged. I don't happen to need that right now although it's potentially useful information. But the Diorisis corpus drops those elements. I don't just mean it drops the tags, it dropps the elements. So if the sentence was <persName>John</persName> loves <persName>Mary</persName>, Diorisis would just give the sentence as loves (at least in Phaedo). Fairly easy to work around for alignment purposes, though.
The more time consuming aspect is the odd way Diorisis handles quotations. It seems to repeat the tokens of each quotation, once in context and then once in a sentence of its own. Except sometimes the repetition is incorporated in an unrelated sentence.
For example, the Homeric quotation in 408a (Republic Book 3) is analyzed inline but then also repeated in another sentence where it's part of the first sentence of 409a ("δικαστὴς δέ γε...") which, unless I'm missing something considerable, is just completely wrong.
I'm manually correcting all this (it comes up as an alignment mismatch and I'm going in and editing the Diorisis XML to remove the duplication). But even without the bad sentence merges, this also means that the vocabulary counts I've previously generated from Diorisis (and in vocabulary-tools) may have doubled up on any words appearing in quotations.
So there's lots more to do with Plato, not least of all the manual curation of lemmatization. But the goal, like that of the Greek Learner Texts Project as a whole, is to have a set of openly-licensed, high-quality, lemmatized texts for extensive reading by language learners.
Collaboration always welcome. Just ping me on the Greek Learner Texts Project Slack workspace.
Ordering Vocabulary by Pericope Dispersion
Jesse Egbert's Plenary at JAECS 2020 is giving me a bunch of ideas of things to try on the New Testament and larger Greek corpora. In this post, I briefly explore text dispersion keyness using pericopes as a way of ordering vocabulary.
Back in Lexical Dispersion in the Greek New Testament Via Gries’s DP I wrote:
My sense is that dispersion might be a useful input to deciding what vocabulary to learn. For example διδαχή or σκότος might be better to learn before ἀρνίον because, even though they all have the same frequency, you are more likely to encounter διδαχή or σκότος in a random book or chapter.
Egbert's plenary (available here after free signup) encouraged me to try a very simple metric instead of frequency: what proportion of text units in the corpus does the word appear in? Egbert emphasises using linguistically meaningful units of text (definitely not fixed-length windows) and pericopes seem perfect for this. There are dispersion measures that allow for varying sizes of text unit (like Gries's DP) but it seemed to me that just seeing what proportion of pericopes the item appears in might be a good measure of the importance to learn (instead of frequency).
This downplays words that might get repeated a lot in just a handful of pericopes and favours those that appear in lots of pericopes even if only one or two times in that pericope. Intuitively this makes sense, A word that appears 10 times in one passage in the New Testament (and nowhere else) isn't as generally useful to learn as a word that appears once in ten different passages. Overall corpus frequency can therefore be misleading because it treats these two cases as the same.
With vocabulary-tools it was trivial to produce a list of all the New Testament lemmas sorted by pericope dispersion.
This gist contains the code and the list:
https://gist.github.com/jtauber/fc4b0476a4c4a94d7cb01d068161892e
Eyeballing the resultant list, it seems a very promising ordering although I welcome comments on anything interesting people notice.
Next steps are:
- quantitative comparison with pure frequency
- application to other lemmatized Greek corpora with meaningful text units similar to pericopes
- try other meaningful text units I have for NT such as books or paragraphs or even sentences
More on Plato After GNT
In the previous post, we looked at lemma and token coverage in the works of Plato assuming knowledge of Greek New Testament vocabulary. Here we graphically look at those results and make an important observation.
For this first chart, I haven't just shown the GNT 100% and 80% but also the 98%, 95%, and 90% levels. The chart shows, assuming you've learned a certain % of GNT lemmas, how many tokens in the works of Plato are from those lemmas plotted against the length of the Plato work. All the plots here are log-log because of the Zipfian nature of word distributions (although it is more important in subsequent plots than this one).
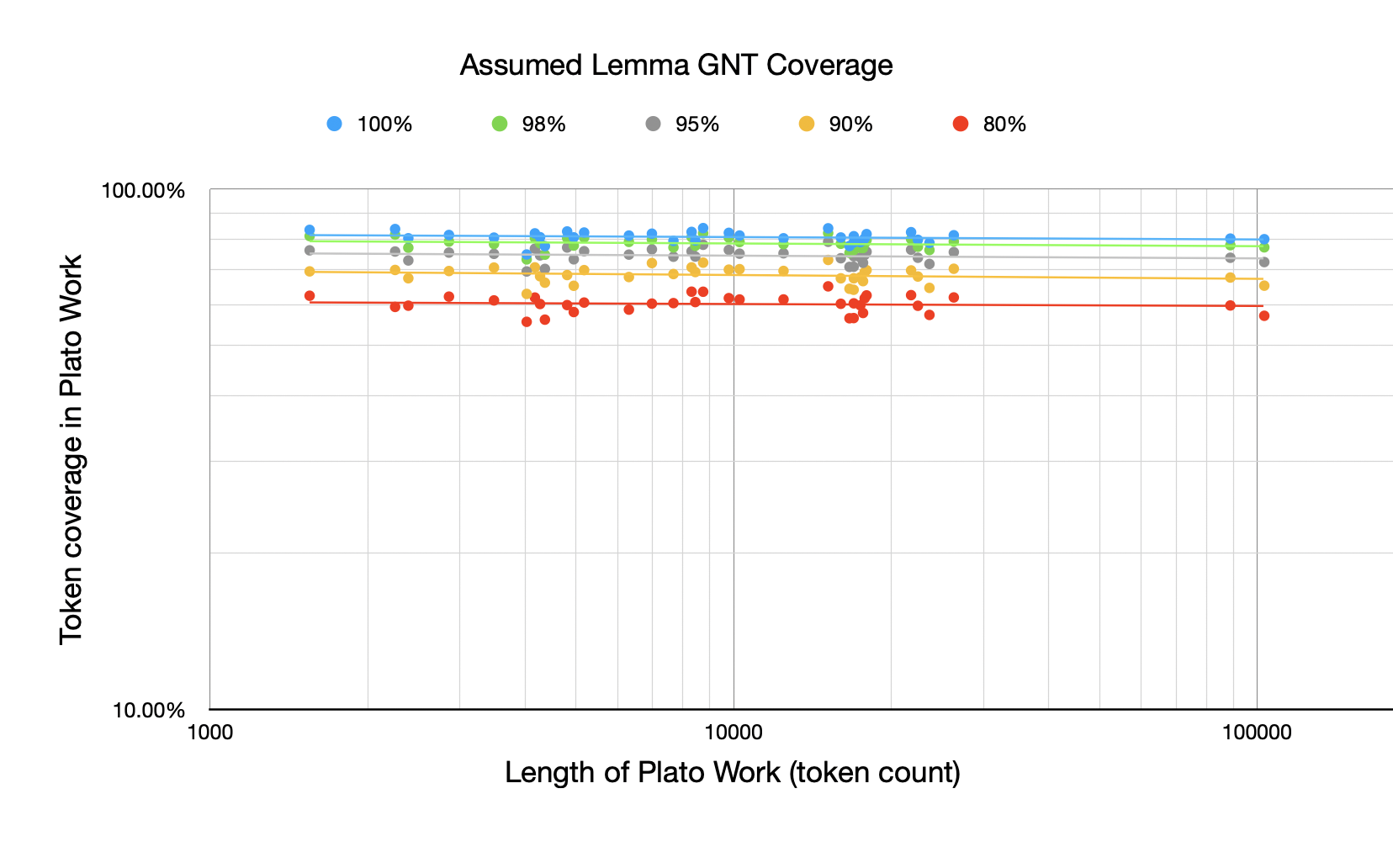
At mentioned in the previous post, I was actually surprised at how little coverage drops off as a function of the length of the Plato work. A 100,000 token work has very similar token coverage than a 5,000 token work.
Visually this can be seen in how horizontal the best-fit lines are above.
However, when it comes to lemma coverage rather than token coverage, the story is very different:
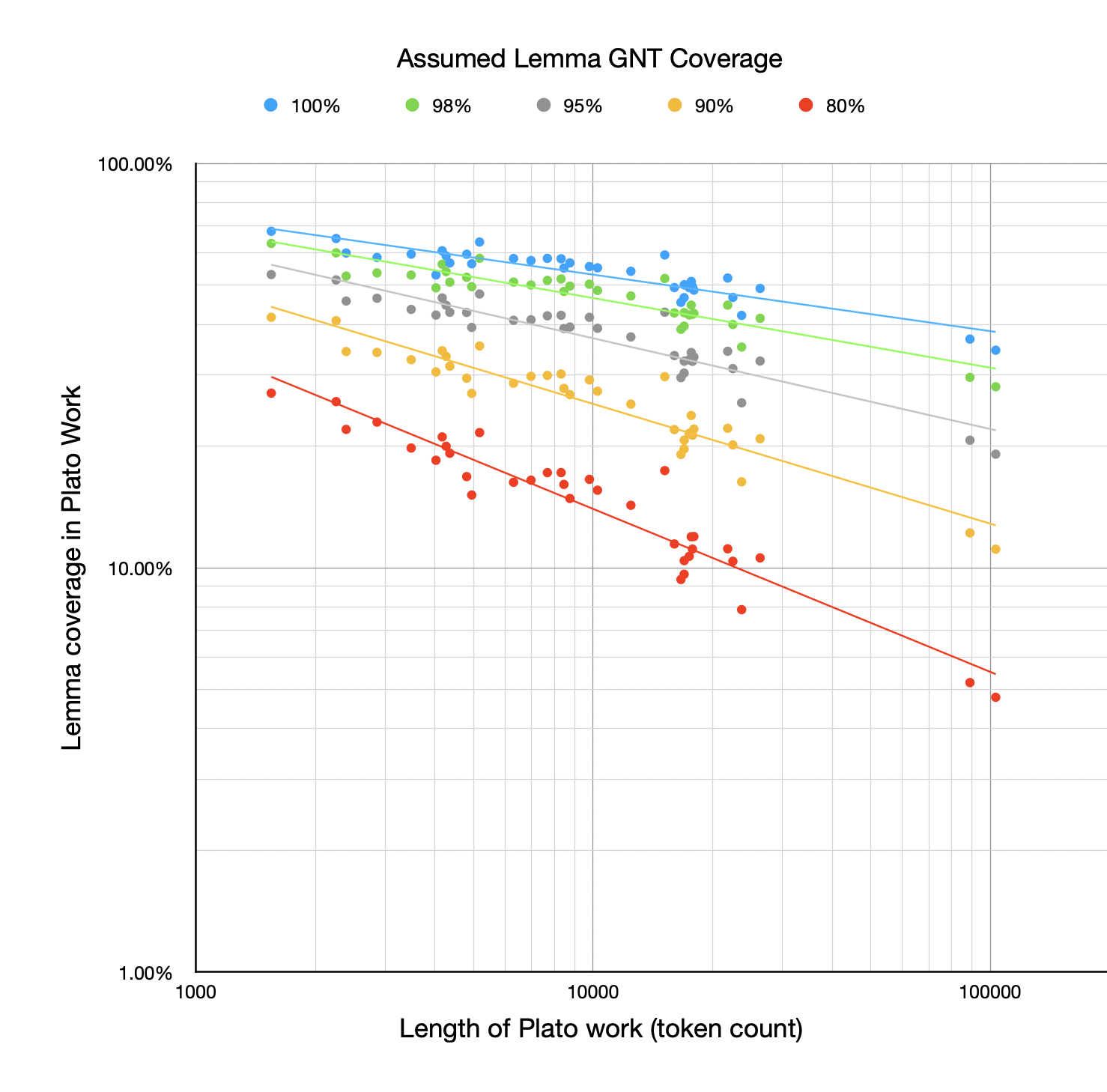
The drop-off above as the Plato work gets longer is quite dramatic (especially when you consider this is a log-log plot). The points fit quite well to a line, though, indicating how Zipfian the distribution is. This demonstrates the clear relationship between the length of the work and how many lemmas you're likely familiar with. The longer a work is, the more distinct lemmas it will use, although they tend to be low frequency within the work (hence how horiztonal the lines in the first chart are).
Notice there are some outliers—some works that seem to have higher coverage than their length would suggest given the best-fit line. I've called out one here, showing just the GNT 80% points and best-fit line (although it's an outlier on the others too):
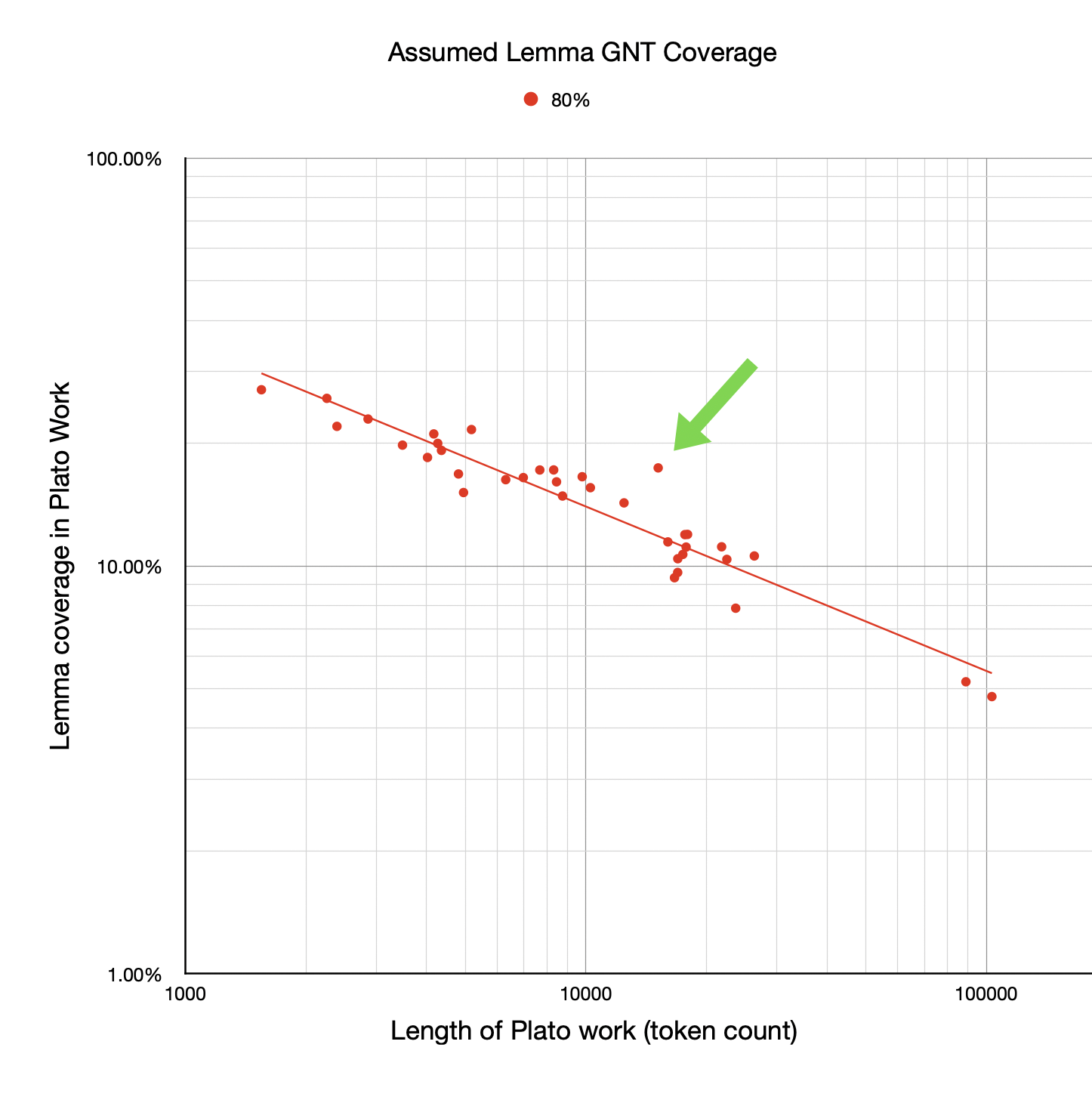
This suggests that this work might be, in some sense, easier for a GNT reader to read compared with other works of Plato. It suggests that perhaps the vocabulary of that particular work is closer to that of the GNT. The data was all there in the previous post but it's a lot easier to spot the outliers graphically.
The work indicated above is Parmenides. I started wonder what it was about that work that made it more "GNT like".
Then I took a step back because I realised there may be a confounding factor here. The statement "this work might be easier for a GNT reader to read compared with other works of Plato" stands but note this might not be a property of any GNT/Parmenides shared vocabulary but rather just the word distribution in Parmenides itself. In other words, Parmenides might just be easier compared with other works of Plato and that might have nothing to do with any vocabulary similarity to the GNT.
So I decided to just plot the token-to-lemma counts in the works of Plato. This doesn't involve the GNT at all, just how many tokens each work in Plato has versus how many unique lemmas that work has.
Here is the result with Parmenides called out:
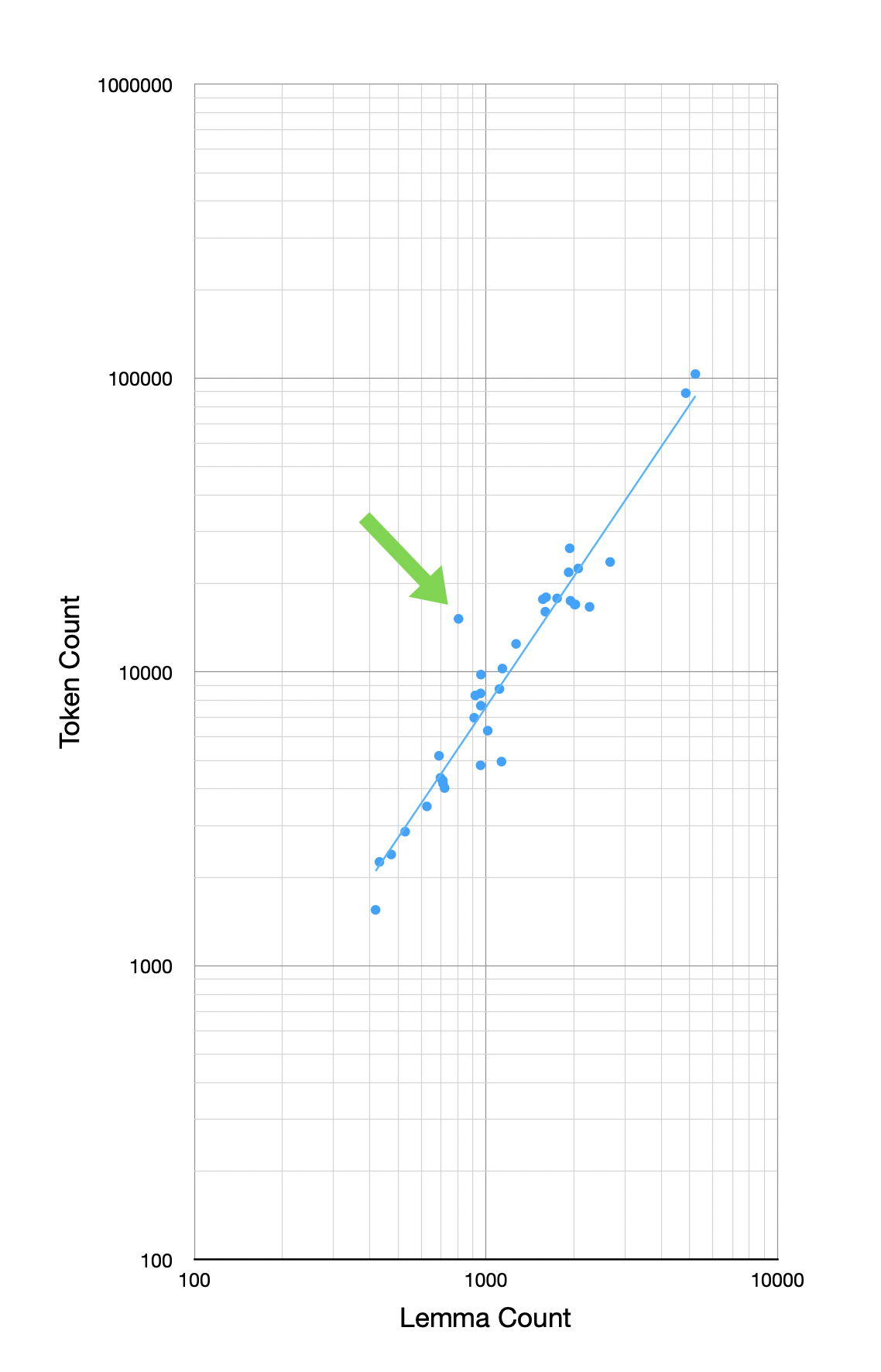
In other words, a large part (and maybe all) of why Parmenides stands off the line in the coverage after GNT is because it simply has fewer lemmas for its overall token count. Its vocabulary is just smaller for its length.
In fact, visually you can see that most of the deviations of works from the line in the early charts maps to corresponding deviations in this chart (which remember has nothing to do with the GNT).
This is just some visual comparison. There are more quantative ways of actually measuring how much the deviations in the first three charts can be explained by those in the last chart. But I'll save that for another post.
The important takeaway for now is that, to the extent some works of Plato might be easier to read after the GNT than others, this probably has little to do with any relationship between their vocabularies, and is more to do with the inherent token-to-lemma ratio of the target work of Plato. It is possible to separate out the effects of each, though, and I will explore that in the future.
Note all the caveats I listed in my previous post about this data. Better lemmatization and richer vocabulary models are still needed.
Plato Vocabulary Coverage After the New Testament
Seumas Macdonald asked me about vocabulary coverage for each work of Plato assuming one has learnt the New Testament vocabulary.
It turned out to be very simple to do with vocabulary-tools and you can now see the script in the repo as examples3.py.
But here let me share the results and give some caveats.
In the table below:
- lemmas is the number of unique lemmas in the work; e.g. Crito has 712 unique lemmas
- tokens is the number of total tokens in the work; e.g. Crito has 4,172 tokens
- GNT lemmas is how many of those lemmas are in the GNT; e.g. 433 (of the 712) lemmas in Crito are also in the GNT
- GNT tokens is how many of the total tokens in the work have lemmas in the GNT; e.g. 3,429 of the 4,172 tokens in Crito have lemmas in the GNT
- % GNT lemmas and % GNT tokens just express those counts as percentages; e.g. 60.81% of the lemmas in Crito are in the GNT and 82.19% of tokens in Crito have lemmas seen in the GNT
| id |
title |
lemmas |
tokens |
GNT lemmas |
GNT tokens |
% GNT lemmas |
% GNT tokens |
| 001 |
Euthyphro |
690 |
5,181 |
441 |
4,274 |
63.91% |
82.49% |
| 002 |
Apology |
1,112 |
8,745 |
631 |
7,357 |
56.74% |
84.13% |
| 003 |
Crito |
712 |
4,172 |
433 |
3,429 |
60.81% |
82.19% |
| 004 |
Phaedo |
1,921 |
21,825 |
1,000 |
18,033 |
52.06% |
82.63% |
| 005 |
Cratylus |
1,607 |
17,944 |
781 |
14,701 |
48.6% |
81.93% |
| 006 |
Theaetetus |
2,072 |
22,489 |
966 |
17,962 |
46.62% |
79.87% |
| 007 |
Sophist |
1,598 |
16,024 |
788 |
12,932 |
49.31% |
80.7% |
| 008 |
Statesman |
2,013 |
16,953 |
937 |
13,384 |
46.55% |
78.95% |
| 009 |
Parmenides |
805 |
15,155 |
478 |
12,738 |
59.38% |
84.05% |
| 010 |
Philebus |
1,567 |
17,668 |
800 |
14,076 |
51.05% |
79.67% |
| 011 |
Symposium |
1,949 |
17,461 |
961 |
13,806 |
49.31% |
79.07% |
| 012 |
Phaedrus |
2,266 |
16,645 |
1,027 |
12,935 |
45.32% |
77.71% |
| 013 |
Alcibiades 1 |
1,138 |
10,264 |
628 |
8,356 |
55.18% |
81.41% |
| 014 |
Alcibiades 2 |
711 |
4,268 |
420 |
3,449 |
59.07% |
80.81% |
| 015 |
Hipparchus |
431 |
2,256 |
281 |
1,890 |
65.2% |
83.78% |
| 016 |
Lovers |
473 |
2,391 |
284 |
1,923 |
60.04% |
80.43% |
| 017 |
Theages |
627 |
3,485 |
374 |
2,811 |
59.65% |
80.66% |
| 018 |
Charmides |
919 |
8,311 |
534 |
6,875 |
58.11% |
82.72% |
| 019 |
Laches |
960 |
7,674 |
559 |
6,100 |
58.23% |
79.49% |
| 020 |
Lysis |
911 |
6,980 |
524 |
5,729 |
57.52% |
82.08% |
| 021 |
Euthydemus |
1,268 |
12,453 |
686 |
10,015 |
54.1% |
80.42% |
| 022 |
Protagoras |
1,753 |
17,795 |
869 |
14,306 |
49.57% |
80.39% |
| 023 |
Gorgias |
1,938 |
26,337 |
951 |
21,467 |
49.07% |
81.51% |
| 024 |
Meno |
961 |
9,791 |
534 |
8,066 |
55.57% |
82.38% |
| 025 |
Hippias Major |
958 |
8,448 |
528 |
6,730 |
55.11% |
79.66% |
| 026 |
Hippias Minor |
698 |
4,360 |
396 |
3,387 |
56.73% |
77.68% |
| 027 |
Ion |
721 |
4,024 |
382 |
3,012 |
52.98% |
74.85% |
| 028 |
Menexenus |
958 |
4,808 |
571 |
3,985 |
59.6% |
82.88% |
| 029 |
Cleitophon |
418 |
1,549 |
284 |
1,293 |
67.94% |
83.47% |
| 030 |
Republic |
4,846 |
88,878 |
1,782 |
71,377 |
36.77% |
80.31% |
| 031 |
Timaeus |
2,666 |
23,662 |
1,122 |
18,644 |
42.09% |
78.79% |
| 032 |
Critias |
1,130 |
4,950 |
638 |
3,997 |
56.46% |
80.75% |
| 033 |
Minos |
528 |
2,859 |
309 |
2,333 |
58.52% |
81.6% |
| 034 |
Laws |
5,227 |
103,193 |
1,804 |
82,652 |
34.51% |
80.09% |
| 035 |
Epinomis |
1,014 |
6,309 |
590 |
5,135 |
58.19% |
81.39% |
| 036 |
Epistles |
2,026 |
16,964 |
1,015 |
13,768 |
50.1% |
81.16% |
It's encouraging how any works are above the 80% level. Here are some caveats, though:
- the Plato lemmatization is from Diorisis so has not been checked and may have errors throwing things off
- the GNT lemmatization is MorphGNT and so even if Diorisis got it “right” it may have a different lemmatization scheme than MorphGNT
- this assumes 100% knowledge of GNT lemmas
- this doesn’t take into account word families nor individual forms
- this coverage calculation theoretically favours shorter works. You can see that in how much lower the % GNT lemmas is for longer works like the Laws and Republic although (perhaps significantly) this doesn’t actually seem to skew token coverage
Favouring shorter works isn't necessary a bad thing if the goal is to find the most readable (by vocabulary) works of Plato post-GNT.
Here's a run of the code only assuming the 80% level of GNT vocabulary rather than the whole thing.
| id |
title |
lemmas |
tokens |
GNT lemmas |
GNT tokens |
% GNT lemmas |
% GNT tokens |
| 001 |
Euthyphro |
690 |
5,181 |
149 |
3,135 |
21.59% |
60.51% |
| 002 |
Apology |
1,112 |
8,745 |
165 |
5,551 |
14.84% |
63.48% |
| 003 |
Crito |
712 |
4,172 |
150 |
2,581 |
21.07% |
61.86% |
| 004 |
Phaedo |
1,921 |
21,825 |
214 |
13,647 |
11.14% |
62.53% |
| 005 |
Cratylus |
1,607 |
17,944 |
192 |
11,208 |
11.95% |
62.46% |
| 006 |
Theaetetus |
2,072 |
22,489 |
215 |
13,416 |
10.38% |
59.66% |
| 007 |
Sophist |
1,598 |
16,024 |
183 |
9,644 |
11.45% |
60.18% |
| 008 |
Statesman |
2,013 |
16,953 |
194 |
9,577 |
9.64% |
56.49% |
| 009 |
Parmenides |
805 |
15,155 |
140 |
9,852 |
17.39% |
65.01% |
| 010 |
Philebus |
1,567 |
17,668 |
187 |
10,209 |
11.93% |
57.78% |
| 011 |
Symposium |
1,949 |
17,461 |
208 |
10,437 |
10.67% |
59.77% |
| 012 |
Phaedrus |
2,266 |
16,645 |
212 |
9,395 |
9.36% |
56.44% |
| 013 |
Alcibiades 1 |
1,138 |
10,264 |
177 |
6,296 |
15.55% |
61.34% |
| 014 |
Alcibiades 2 |
711 |
4,268 |
142 |
2,566 |
19.97% |
60.12% |
| 015 |
Hipparchus |
431 |
2,256 |
111 |
1,339 |
25.75% |
59.35% |
| 016 |
Lovers |
473 |
2,391 |
104 |
1,427 |
21.99% |
59.68% |
| 017 |
Theages |
627 |
3,485 |
124 |
2,129 |
19.78% |
61.09% |
| 018 |
Charmides |
919 |
8,311 |
158 |
5,277 |
17.19% |
63.49% |
| 019 |
Laches |
960 |
7,674 |
165 |
4,632 |
17.19% |
60.36% |
| 020 |
Lysis |
911 |
6,980 |
150 |
4,204 |
16.47% |
60.23% |
| 021 |
Euthydemus |
1,268 |
12,453 |
181 |
7,640 |
14.27% |
61.35% |
| 022 |
Protagoras |
1,753 |
17,795 |
195 |
10,973 |
11.12% |
61.66% |
| 023 |
Gorgias |
1,938 |
26,337 |
205 |
16,301 |
10.58% |
61.89% |
| 024 |
Meno |
961 |
9,791 |
159 |
6,042 |
16.55% |
61.71% |
| 025 |
Hippias Major |
958 |
8,448 |
154 |
5,123 |
16.08% |
60.64% |
| 026 |
Hippias Minor |
698 |
4,360 |
134 |
2,446 |
19.2% |
56.1% |
| 027 |
Ion |
721 |
4,024 |
133 |
2,236 |
18.45% |
55.57% |
| 028 |
Menexenus |
958 |
4,808 |
161 |
2,877 |
16.81% |
59.84% |
| 029 |
Cleitophon |
418 |
1,549 |
113 |
966 |
27.03% |
62.36% |
| 030 |
Republic |
4,846 |
88,878 |
252 |
53,090 |
5.2% |
59.73% |
| 031 |
Timaeus |
2,666 |
23,662 |
210 |
13,555 |
7.88% |
57.29% |
| 032 |
Critias |
1,130 |
4,950 |
171 |
2,872 |
15.13% |
58.02% |
| 033 |
Minos |
528 |
2,859 |
121 |
1,776 |
22.92% |
62.12% |
| 034 |
Laws |
5,227 |
103,193 |
250 |
58,891 |
4.78% |
57.07% |
| 035 |
Epinomis |
1,014 |
6,309 |
165 |
3,700 |
16.27% |
58.65% |
| 036 |
Epistles |
2,026 |
16,964 |
211 |
10,229 |
10.41% |
60.3% |
The Plato coverage generally drops from around 80% to 60% which suggests it might be worth "topping up" one's vocabulary with some common Plato words not in the GNT before embarking on a specific work. It would be easy to generate such a list with vocabulary-tools.
But it was quite striking to me in both tables just how little the token % drops due to length (in contrast to the lemma %).
This just goes to show that longer works introduce a lot of new words but very sparsely (probably with only one occurrence in many cases).
I might explore that graphically in a follow-up post.
A Tour of Greek Morphology: Part 48
Part forty-eight of a tour through Greek inflectional morphology to help get students thinking more systematically about the word forms they see (and maybe teach a bit of general linguistics along the way).
We previously introduced the (θ)η-aorists. In this post, we'll mention the stem variants and then go over some counts.
In terms of stem variants, we first of all have δέω, where we find the infinitive δεθῆναι alongside the 1SG ἐδεήθην and 3SG ἐδεήθη. The infinitive form suggests a stem of δε-θη whereas the finite forms suggest a stem of ἐ-δεη-θη with an extra η.
Secondly, we have two 3SG forms of ἁρπάζω: ἡρπάγη and ἡρπάσθη.
Finally we have ἀνοίγω with its confused augmentation (which we've seen in other aorists) and also both a θ and non-θ form. Putting aside the ἠνοι- vs ἀνεῳ- vs ἠνεῳ- variation, we have 3SG ἠνοίχθη alongside ἠνοίγη and 3PL ἠνοίχθησαν alongside ἠνοίγησαν.
Notice that in both the ἁρπάζω and ἀνοίγω cases, we have a non-θ form with γ before the η. We'll look at the letters we find before η and θη later in this post.
But first let's do our usual counts of tokens and lemmas.
| class |
# lemmas |
# tokens |
# hapakes |
| -θη- |
250 |
954 |
130 |
| -η- |
34 |
79 |
19 |
As one can see, the non-θ forms are more rare lexically and the lexemes that do take them occur less frequently. They both, however, seem productive.
|
-θη- |
-η- |
| INF |
166 |
4 |
| 1SG |
29 |
6 |
| 2SG |
8 |
2 |
| 3SG |
489 |
43 |
| 1PL |
30 |
5 |
| 2PL |
44 |
3 |
| 3PL |
188 |
16 |
The distribution above is what we might expect except for the INF which are disproportionately -θη-. This is not due to a single lexical item (unlike the 3SG where ἀπεκρίθη dominates).
This will be worth further investigation but we have other things to cover first. For example, is there any phonological reason why a non-θ form might be used rather than a θ-form? We saw previously, for example, that the existence or absence of the sigma in the alphathematic aorists was largely (although not entirely) predicted by the preceding letter.
It turns out, at least in our text (we'll look more broadly later) there's quite a strong correlation between whether a θ is found or not and what the preceding letter is.
For example, if the preceding letter is any of the vowels ε η ι ο υ ω, then we always find the θη form in the SBLGNT. α is the only exception and even then only in one lexical item out of 14, the κατακαίω form κατεκάη. (Notably κατεκαύ(σ)θη is more common elsewhere but we'll have to wait a little to discuss καίω forms in general)
If the preceding letter is σ, then we always find the θη form. This is actually the most likely letter to precede θ by far, followed by η.
ξ ψ and ζ don't appear in (θ)η aorists in the SBLGNT. Nor do δ τ or θ.
Amongst the velars: κ doesn't appear in (θ)η aorists in the SBLGNT but γ and χ both do. γ is always followed directly by η (and in fact the bigram γθ never appears in the SBLGNT at all). In contrast, χ always takes the θ form (which might be explained by an underlying κ or γ becoming χ because of the following θ but this doesn't explain why the θ would be absent in the -γ-η- instances).
Amongst the bilabials: both π and β are always followed directly by η (and neither πθ nor βθ appear as bigrams in the SBLGNT). φ however is found both in θη and η forms with a slight preference for φθη over φη.
This leaves our resonances: the liquids λ and ρ, and the nasals μ and ν. The bigram λθ is definitely allowed in Greek but we only find -λ-η- aorists, not -λ-θη-. With ν and ρ we find both θ and non-θ forms. There are no μ examples in the SBLGNT, nor do we find the bigram μθ.
Here's a summary with lexeme counts:
|
-θη- |
-η- |
| α |
13 |
1 |
| ε |
21 |
- |
| η |
80 |
- |
| ι |
17 |
- |
| ο |
11 |
- |
| υ |
26 |
- |
| ω |
52 |
- |
| σ |
108 |
- |
| ξ |
- |
- |
| ψ |
- |
- |
| ζ |
- |
- |
| τ |
- |
- |
| δ |
- |
- |
| θ |
- |
- |
| κ |
- |
- |
| γ |
- |
12 |
| χ |
37 |
- |
| β |
- |
2 |
| π |
- |
3 |
| φ |
16 |
10 |
| λ |
- |
6 |
| ρ |
6 |
8 |
| μ |
- |
- |
| ν |
16 |
3 |
Clearly there are some patterns here. Vowels, σ, and the aspirated stops strongly (or even entirely) favour -θη-. The non-aspirated stops seem to entirely favour a plain η. The resonances are a mixed bag.
There are definitely some correlations but it's unclear what the casual relationship is. And it raises the important question of where the letter before the θ (or η) comes from in the first place. This relates more broadly to the question of the aorist stem. What is the relationship between the aorist stems used in the active, middle and (θ)η forms? In the next post, we'll start to explore that. Then, after reviewing all our endings so far, we'll move on to the even bigger question: what's the relationship between the aorist stem and the present stem?
|